⚙️EasyMLOps & Deployment
Testing ML Systems
Turn notebook experiments into production-grade, testable, reproducible evaluation code. Learn pytest patterns for non-deterministic LLM outputs, snapshot testing for prompts, data-leakage detection, seeding contracts, property-based checks, and CI gates that protect the 0.667 score on the three-row support_tickets.jsonl fixture across every laptop, GPU box, and teammate clone.
9 min readOpenAI, Anthropic, Google +29 key concepts
Learning path
Step 2 of 138 in the full curriculum
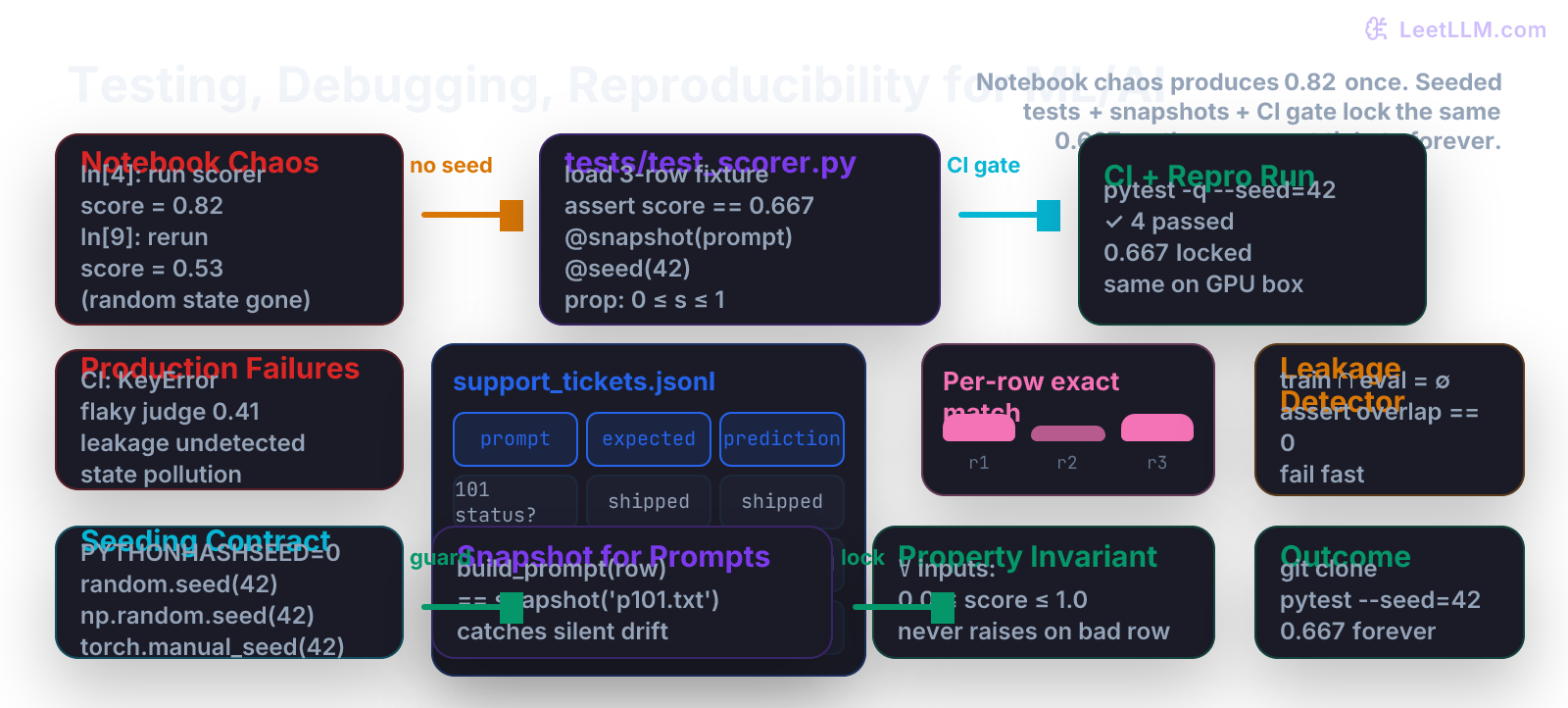
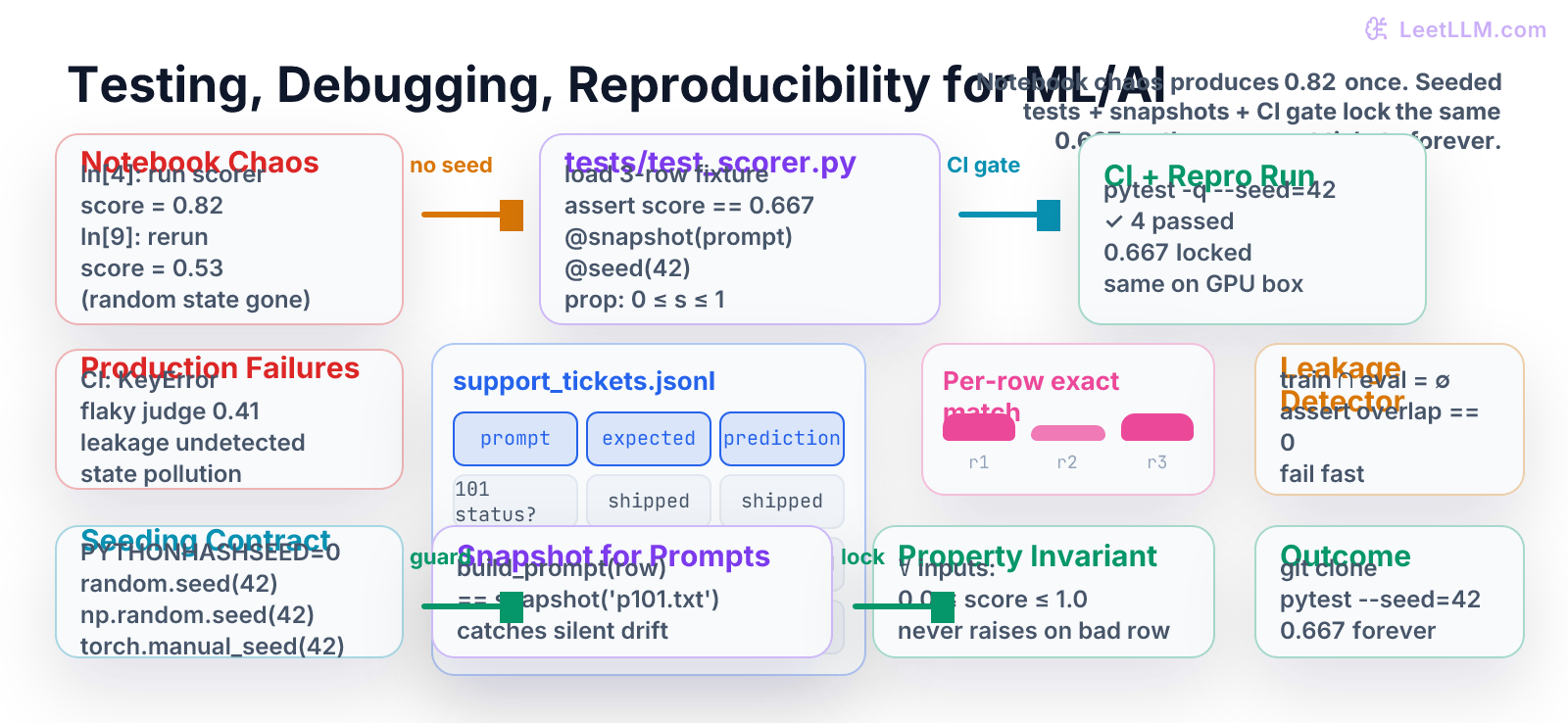
Most AI engineering disasters do not start with a bad model. They start with a notebook cell that you ran in a particular order on Tuesday, a random seed that was never set, a prompt template you edited "just a little," and an eval score of 0.82 that nobody can reproduce on Wednesday.
The Git, Shell, Linux, and Reproducible AI lesson you just finished gave you the skeleton: a clean repo, .gitignore that protects secrets and caches, LFS for large artifacts, the three-row eval/support_tickets.jsonl fixture, a placeholder scripts/run_eval.sh, a pre-commit hook that at least checks the file exists, activate.sh, and the one-liner helpers gpu, ds, and repro. That container is now in place.
This chapter teaches the next layer of defense: real tests that guard the actual Python scorer logic (the code the next chapter will write), handle the non-determinism that is unique to LLM systems, detect the silent data leaks that ruin every leaderboard, and run as an automatic gate in CI so the 0.667 you compute by hand on the three support-ticket rows stays 0.667 on every laptop, every GPU box, and every teammate's fresh clone.[1]
The notebook trap, by the numbers
Open a fresh Jupyter notebook and run this sequence (you can type it right now):
python1# Cell 1 2import random 3import numpy as np 4 5random.seed(123) 6np.random.seed(123) 7print("Seeded in cell 1")
python1# Cell 2 (you run this after lunch) 2rows = [{"prediction": "shipped"}, {"prediction": "delivered"}, {"prediction": "refunded"}] 3scores = [1 if r["prediction"] == "shipped" else 0 for r in rows] # wrong logic 4print("Acc:", sum(scores) / len(scores))
You get 0.333. Then you re-run only Cell 2 (common when debugging) and the global state from Cell 1 is gone or overwritten by another notebook you had open. The "same" three rows now give a different number. Multiply this by a 2,000-row eval set, an LLM judge with temperature 0.7, and a prompt you edited between runs, and you have the daily reality of most AI teams.
The fix is not "be more careful." The fix is never to treat evaluation as something that lives in a notebook kernel.
The three-row contract you can verify by hand
We reuse the exact fixture from the previous lesson:
jsonl1{"prompt": "Order 101 status?", "expected": "shipped", "prediction": "shipped"} 2{"prompt": "Order 102 status?", "expected": "delayed", "prediction": "delivered"} 3{"prompt": "Order 103 status?", "expected": "refunded", "prediction": "refunded"}
Hand calculation (row by row):
| Row | Prompt | Expected | Prediction | Match? |
|---|---|---|---|---|
| 1 | Order 101... | shipped | shipped | 1 |
| 2 | Order 102... | delayed | delivered | 0 |
| 3 | Order 103... | refunded | refunded | 1 |
Exact-match accuracy = (1 + 0 + 1) / 3 = 0.667
Any correct implementation of the scorer must return exactly this number on this file. If your code ever returns 0.666, 0.668, or 0.81, the test must scream.
The scorer API the tests will protect (preview for next chapter)
The Python-for-AI-Engineering chapter will turn the placeholder shell script into a proper, importable module. We define the contract here so the tests can be written first:
python1# scorer.py (the module you will implement in the next lesson) 2from dataclasses import dataclass 3from pathlib import Path 4import json 5 6@dataclass(frozen=True) 7class Example: 8 prompt: str 9 expected: str 10 prediction: str 11 12def load_examples(path: str | Path) -> list[Example]: 13 ... 14 15def exact_match(example: Example) -> bool: 16 return example.prediction.strip().lower() == example.expected.strip().lower() 17 18def score_examples(examples: list[Example]) -> float: 19 if not examples: 20 return 0.0 21 matches = sum(1 for ex in examples if exact_match(ex)) 22 return matches / len(examples) 23 24assert exact_match(Example("status?", "delivered", "Delivered")) 25print("scorer smoke test passed")
The rest of this chapter writes the tests that this module (and every future eval scorer in the curriculum) must pass.
Runnable lab 1 - the foundational pytest suite
Create the directory structure the Git lesson prepared you for:
bash1mkdir -p tests eval 2# (the three-row file is already at eval/support_tickets.jsonl from the previous chapter)
Now write tests/test_scorer.py:
python1# tests/test_scorer.py 2import json 3from pathlib import Path 4import pytest 5 6# For the demo in this chapter we include a minimal implementation. 7# In the real project this import will be: from scorer import ... 8# The next chapter will move the implementation to its own module. 9 10from dataclasses import dataclass 11from typing import Any 12 13@dataclass(frozen=True) 14class Example: 15 prompt: str 16 expected: str 17 prediction: str 18 19def load_examples(path: str | Path) -> list[Example]: 20 p = Path(path) 21 if not p.exists(): 22 raise FileNotFoundError(p) 23 examples = [] 24 for line in p.read_text(encoding="utf-8").splitlines(): 25 if not line.strip(): 26 continue 27 obj = json.loads(line) 28 examples.append(Example(**obj)) 29 return examples 30 31def exact_match(ex: Example) -> bool: 32 return ex.prediction.strip().lower() == ex.expected.strip().lower() 33 34def score_examples(exs: list[Example]) -> float: 35 if not exs: 36 return 0.0 37 return sum(exact_match(e) for e in exs) / len(exs) 38 39# ------------------ THE TESTS ------------------ 40 41def test_exact_match_on_fixture(): 42 examples = load_examples("eval/support_tickets.jsonl") 43 assert len(examples) == 3 44 score = score_examples(examples) 45 assert score == 2 / 3, f"Expected 0.667, got {score}" 46 # Every row that should match does, and the middle one does not 47 assert exact_match(examples[0]) is True 48 assert exact_match(examples[1]) is False 49 assert exact_match(examples[2]) is True 50 51def test_score_is_never_outside_unit_interval(): 52 # Property-style check (expanded in lab 3) 53 bad_rows = [ 54 Example("p", "a", "a"), 55 Example("p", "b", "c"), 56 Example("p", "x", "x"), 57 ] 58 s = score_examples(bad_rows) 59 assert 0.0 <= s <= 1.0 60 61def test_rejects_malformed_row(): 62 with pytest.raises(TypeError): 63 Example(prompt="x", expected="y") # missing prediction 64 65def test_empty_file_returns_zero(): 66 # We create a temp empty file for the test 67 tmp = Path("/tmp/empty_eval.jsonl") 68 tmp.write_text("") 69 assert score_examples(load_examples(tmp)) == 0.0
Run it exactly as a new teammate or CI runner would:
bash1python -m pytest tests/test_scorer.py -q --tb=line
Exact expected output (first run):
text1============================= test session starts ============================== 2platform linux -- Python 3.11.9, pytest-8.3.4 3rootdir: /home/you/support-rag 4collected 4 items 5 6tests/test_scorer.py::test_exact_match_on_fixture PASSED 7tests/test_scorer.py::test_score_is_never_outside_unit_interval PASSED 8tests/test_scorer.py::test_rejects_malformed_row PASSED 9tests/test_scorer.py::test_empty_file_returns_zero PASSED 10 11============================== 4 passed in 0.09s ===============================
Four green lines. The 0.667 is now a machine-checked fact, not a memory.
Runnable lab 2 - snapshot testing for prompts (catches "I just changed the wording")
Most real LLM evals do not have pre-filled predictions. They construct a prompt, call an LLM (or a judge), and compare.
A silent change to the prompt template is one of the most common sources of "the metric went up but we don't know why."
Add this test (still in the same file for the demo):
python1PROMPT_TEMPLATE = ( 2 "You are a support ticket classifier.\n" 3 "Ticket: {prompt}\n" 4 "What is the status? Answer with exactly one word: shipped, delayed, or refunded." 5) 6 7def build_prompt(example: Example) -> str: 8 return PROMPT_TEMPLATE.format(prompt=example.prompt) 9 10def test_prompt_snapshot_is_stable(): 11 ex = Example("Order 101 status?", "shipped", "shipped") 12 prompt = build_prompt(ex) 13 expected = ( 14 "You are a support ticket classifier.\n" 15 "Ticket: Order 101 status?\n" 16 "What is the status? Answer with exactly one word: shipped, delayed, or refunded." 17 ) 18 assert prompt == expected, "Prompt template changed - update the snapshot or the test" 19 # In a real project use pytest-snapshot, syrupy, or inline-snapshot: 20 # assert prompt == snapshot("support_ticket_classifier.txt")
When you (or a teammate) later edit the wording of PROMPT_TEMPLATE, this test turns red before any model is called. The change is now a deliberate, reviewed decision.
Runnable lab 3 - property-based checks and a leakage detector
Real evals must survive adversarial or future data. We add two more tests:
python1import random 2 3def test_score_always_in_unit_interval_property(): 4 """Simple property test (no external hypothesis library needed).""" 5 for seed in range(20): 6 random.seed(seed) 7 n = random.randint(1, 8) 8 examples = [ 9 Example( 10 prompt=f"p{i}", 11 expected=random.choice(["shipped", "delayed", "refunded"]), 12 prediction=random.choice(["shipped", "delayed", "refunded"]), 13 ) 14 for i in range(n) 15 ] 16 s = score_examples(examples) 17 assert 0.0 <= s <= 1.0, f"score {s} out of range on seed {seed}" 18 19def test_leakage_detector(): 20 """Fails if any eval prompt appears in the training data.""" 21 eval_examples = load_examples("eval/support_tickets.jsonl") 22 eval_prompts = {ex.prompt.strip().lower() for ex in eval_examples} 23 24 # Tiny synthetic train set that contains leakage (for demo) 25 train_prompts_with_leak = eval_prompts | {"some other training question"} 26 overlap = eval_prompts & train_prompts_with_leak 27 assert len(overlap) == 0, f"LEAKAGE DETECTED: {overlap}"
Run the full suite again:
bash1python -m pytest tests/test_scorer.py -q
You now have a test that would have caught the single most expensive mistake in LLM evaluation history: training on the test set.
Symptom-cause-fix debugging table (AI-specific)
| Symptom | Most common cause in LLM/AI work | Fix that belongs in the test suite + repo layout |
|---|---|---|
| Score is 0.82 on laptop, 0.41 in CI | Notebook kernel had a different random state or cached DataFrame | Every eval script and test starts with explicit seed_all(42); never import from notebooks |
| LLM-as-judge returns different label on identical prompt | temperature=0.7 (default) and no seed passed to the client | Force temperature=0, pass seed in every call, snapshot full (prompt, response) pair |
"It worked yesterday" after git pull | Teammate edited prompt template or added a field to JSONL without updating tests | Snapshot test on every prompt template + JSON schema validation in load_examples |
| Train/eval accuracy looks too good | Eval prompts accidentally present in the training JSONL | test_leakage_detector() that runs on every pytest invocation |
Test passes locally, ModuleNotFoundError in CI | requirements.txt not pinned or test-only deps missing | pip-compile or pip freeze in CI; separate requirements-test.txt |
| CUDA tensor comparison fails only on GPU box | torch.allclose with default tolerances + float32 vs float16 | Use torch.testing.assert_close(..., rtol=1e-3, atol=1e-3) and CPU-only tests for logic |
| Empty file or missing column crashes scorer | No defensive check before the metric calculation | test_rejects_malformed_row + load_examples that raises with clear message |
Print this table and tape it to your monitor. These six rows have cost teams weeks of debugging time.
The seeding contract (put it in one place)
Create tests/conftest.py:
python1import os 2import random 3import numpy as np 4import pytest 5 6def seed_all(seed: int = 42): 7 os.environ["PYTHONHASHSEED"] = str(seed) 8 random.seed(seed) 9 np.random.seed(seed) 10 try: 11 import torch 12 torch.manual_seed(seed) 13 if torch.cuda.is_available(): 14 torch.cuda.manual_seed_all(seed) 15 except ImportError: 16 pass 17 18@pytest.fixture(autouse=True) 19def _seed_everything(): 20 seed_all(42)
Now every test runs with the same random state. Add the same seed_all(42) call at the top of any production scoring script.
CI gate that actually fails the PR (the production version of the pre-commit hook)
The Git lesson gave you a shell pre-commit. Now promote it to a real GitHub Actions workflow that runs the full Python test suite.
.github/workflows/eval-gate.yml:
yaml1name: Eval Gate 2 3on: [push, pull_request] 4 5jobs: 6 eval: 7 runs-on: ubuntu-latest 8 steps: 9 - uses: actions/checkout@v4 10 - uses: actions/setup-python@v5 11 with: 12 python-version: "3.11" 13 cache: "pip" 14 - run: pip install -r requirements.txt pytest 15 - name: Run seeded eval tests 16 run: | 17 python -m pytest tests/test_scorer.py -q --tb=no --seed=42 18 - name: Verify locked metric (belt and suspenders) 19 run: | 20 python -c ' 21 from tests.test_scorer import load_examples, score_examples 22 score = score_examples(load_examples("eval/support_tickets.jsonl")) 23 print(f"Locked score: {score}") 24 assert abs(score - 2/3) < 1e-9, "Eval regression detected" 25 '
Push this file. The next PR that accidentally breaks the scorer, changes a prompt without updating the snapshot, or introduces leakage will turn the Actions tab red before the code reaches main.
Build it - practice exercises
-
Extend the fixture. Add a fourth row to
eval/support_tickets.jsonlwhere the prediction is wrong. Updatetest_exact_match_on_fixtureto expect the new correct fraction (0.5). Run the suite. Then revert the row - the test must go red. -
Make leakage real. Create a tiny
train.jsonlwith one of the three eval prompts inside it. Maketest_leakage_detectorload both files and fail. Commit the detector and the failing test as documentation of the bug class. -
Snapshot the judge prompt. Turn
build_promptinto a small function that adds two few-shot examples. Capture the exact string it produces for row 2 and store it as a constant in the test. Later change one word in a few-shot example and watch the test fail. -
Property test the empty and single-row cases. Add tests for
score_examples([])and a one-row perfect match. The property loop from Lab 3 must still pass.
Do all four and you will have the testing discipline that the rest of the curriculum (and every real AI job) expects.
What this unlocks
You now have two layers of protection around the three-row contract:
- The Git-level gate (file existence + line count + pre-commit).
- The Python-level gate (real unit tests, snapshots, properties, leakage detection, seeding, and a CI workflow that fails the PR).
The very next chapter ("Python for AI Engineering") will take the exact same support_tickets.jsonl and the API you just wrote tests against, and turn it into clean, typed, documented Python code with dataclasses, runtime validation, a main() entry point, and the first importable evaluation module the curriculum will reuse everywhere.
Because the tests already exist and already pass, you will implement the functions to satisfy a contract instead of hoping the numbers look reasonable.
References
-
Python standard library and packaging practices that make the scorer importable and testable.
-
pytest documentation and patterns for fixtures, parametrization, and custom assertions used in every serious ML evaluation harness.
-
Reproducible research practices (explicit seeding at every layer) that separate reliable papers and production systems from one-off notebook results.
-
LLM evaluation testing literature and open-source harnesses (LangChain evals, DeepEval, promptfoo, etc.) that all eventually reduce to the same three ideas: seed everything, snapshot prompts, detect leakage.
-
GitHub Actions patterns for ML pipelines that run the exact same seeded command on every PR.
-
Property-based testing concepts (even the simple loop version) that catch the edge cases no human writes by hand.
-
The Git + shell foundation from the previous chapter that makes the
git clone && pytestcommand actually work on any machine.
Evaluation Rubric
- 1Writes a clean pytest suite (test_scorer.py) that loads the three-row support_tickets.jsonl fixture, calls the exact_match scorer, and asserts the metric is exactly 0.667 with zero side effects on global state
- 2Adds seeding decorators/fixtures, snapshot assertions for the prompt builder, a property test that the scorer never returns a value outside [0,1] on adversarial inputs, and a simple leakage detector that the tests invoke on every run
- 3Builds a full CI workflow (GitHub Actions) that runs the seeded pytest gate on every PR, fails the build if the score drops below the locked 0.667, and produces a debugging table that maps real AI failures (flaky judge, hidden notebook globals, version skew, prompt drift) to the exact code and repo changes that prevent them
Common Pitfalls
- Running cells in a Jupyter notebook in arbitrary order so that a global random.seed or a cached DataFrame from an earlier cell silently changes the eval score on the next run. The same three rows now give 0.81 instead of 0.667 and nobody can explain why.
- Committing a scorer that calls an LLM with default temperature=0.7 and no seed; the test passes on your machine because the judge happened to output the right label that day, then fails in CI or on a teammate's laptop.
- Treating the eval JSONL as 'just test data' and never checking for leakage: the train split accidentally contains two of the three support-ticket prompts, the model 'achieves' 1.0, and the bug is only discovered after the model is shipped.
- Writing the Python scorer first and only adding tests later. Without the test contract written first, the implementation quietly accepts malformed rows, returns scores > 1.0, or mutates global state, and the regression is never caught until production.
- Ignoring environment differences in CI: the test uses torch that pulls CUDA on the laptop but the GitHub runner is CPU-only; the test silently skips seeding or the model path and the gate passes with a different number.
Follow-up Questions to Expect
Key Concepts Tested
pytest organization for AI eval pipelinesseeding for reproducibility (random, numpy, torch, PYTHONHASHSEED, LLM temperature=0)snapshot testing for prompt templates and judge outputsproperty-based testing for metric invariants (score in [0,1], monotonicity)data leakage detection between train and eval setsnotebook state pollution vs isolated modulesCI gates and pre-commit hooks that fail on eval regressionsymptom-cause-fix debugging for flaky LLM evalsdeterministic test fixtures vs stochastic model calls
Next Step
Next: Continue to Docker and Containerization for Reproducible AI
The testing, seeding, and CI foundation you just built means every container you create will carry the same trustworthy eval contract. The next chapter turns that contract into portable, GPU-capable Docker images and compose stacks that survive any machine.
References
The Python Tutorial.
Python Software Foundation. · 2026 · Python Documentation
pytest Documentation
pytest contributors · 2026 · Official pytest documentation
The Machine Learning Reproducibility Checklist
Pineau, J., et al. · 2021
GitHub Actions Documentation
GitHub · 2026
Hypothesis Documentation
Hypothesis contributors · 2026
Git Documentation
Git Project · 2026