LeetLLMContent EngineeringAI Engineering+2
How We Built LeetLLM
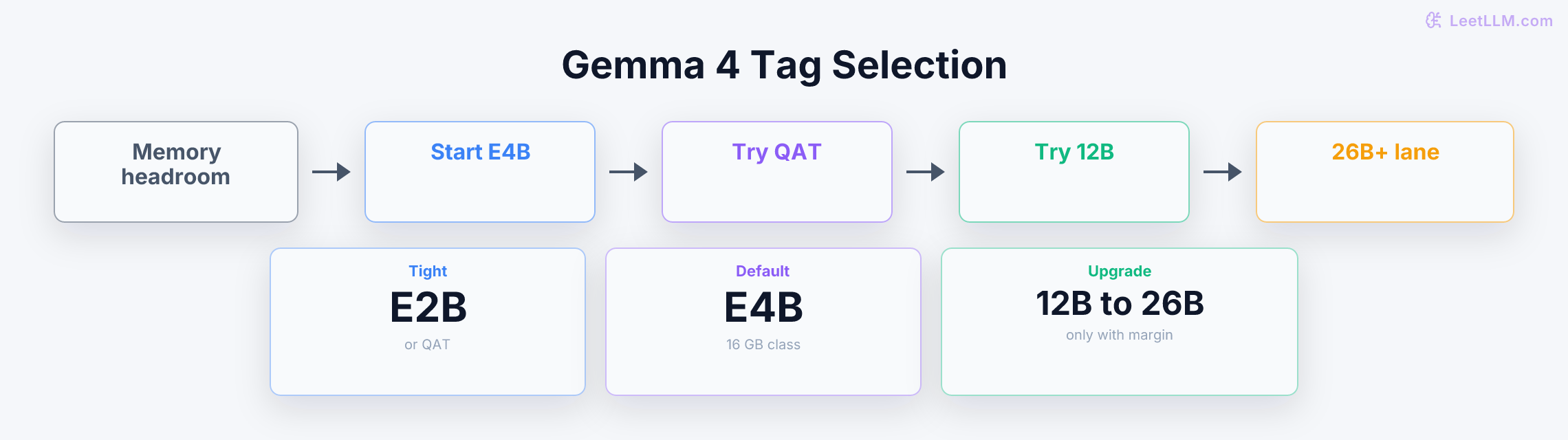
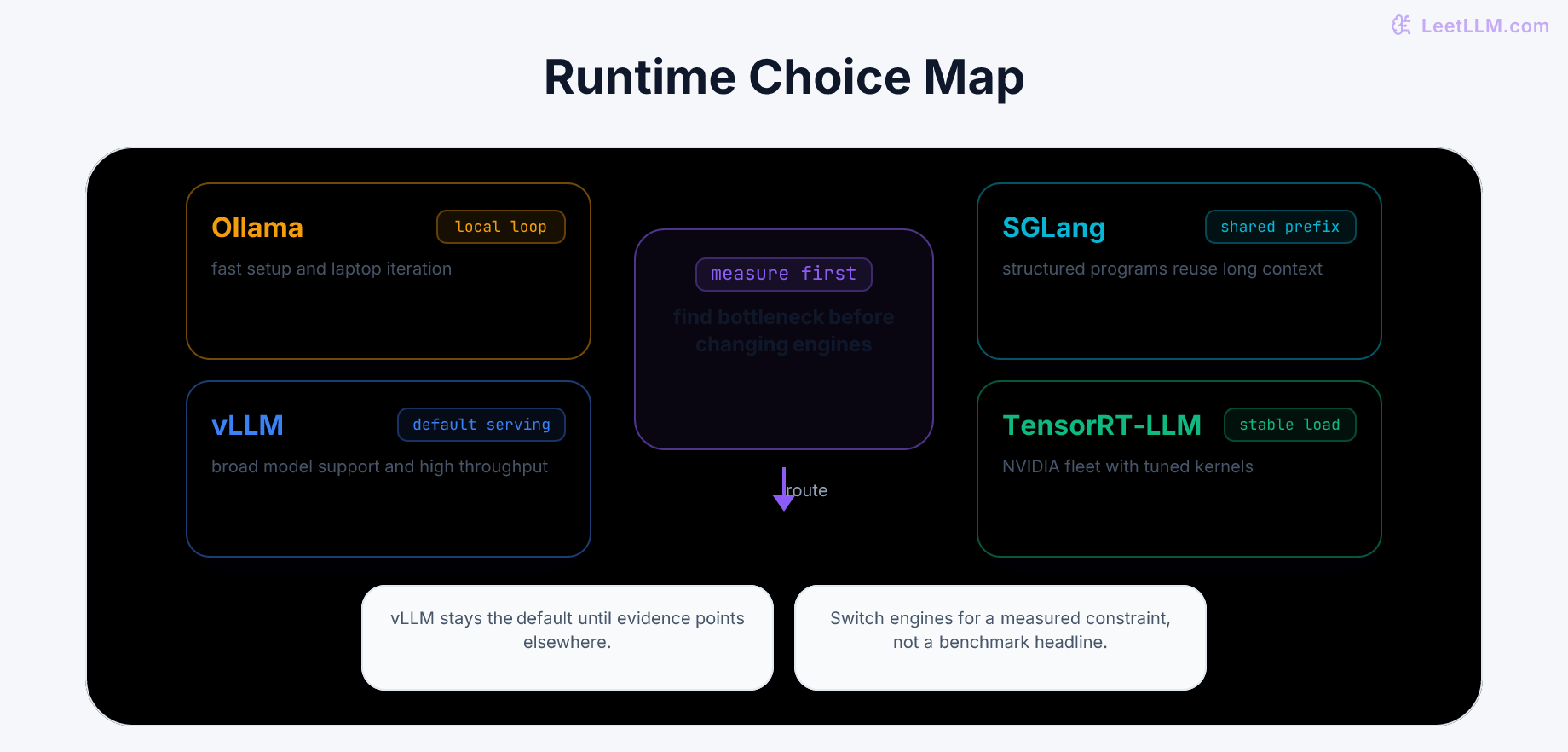
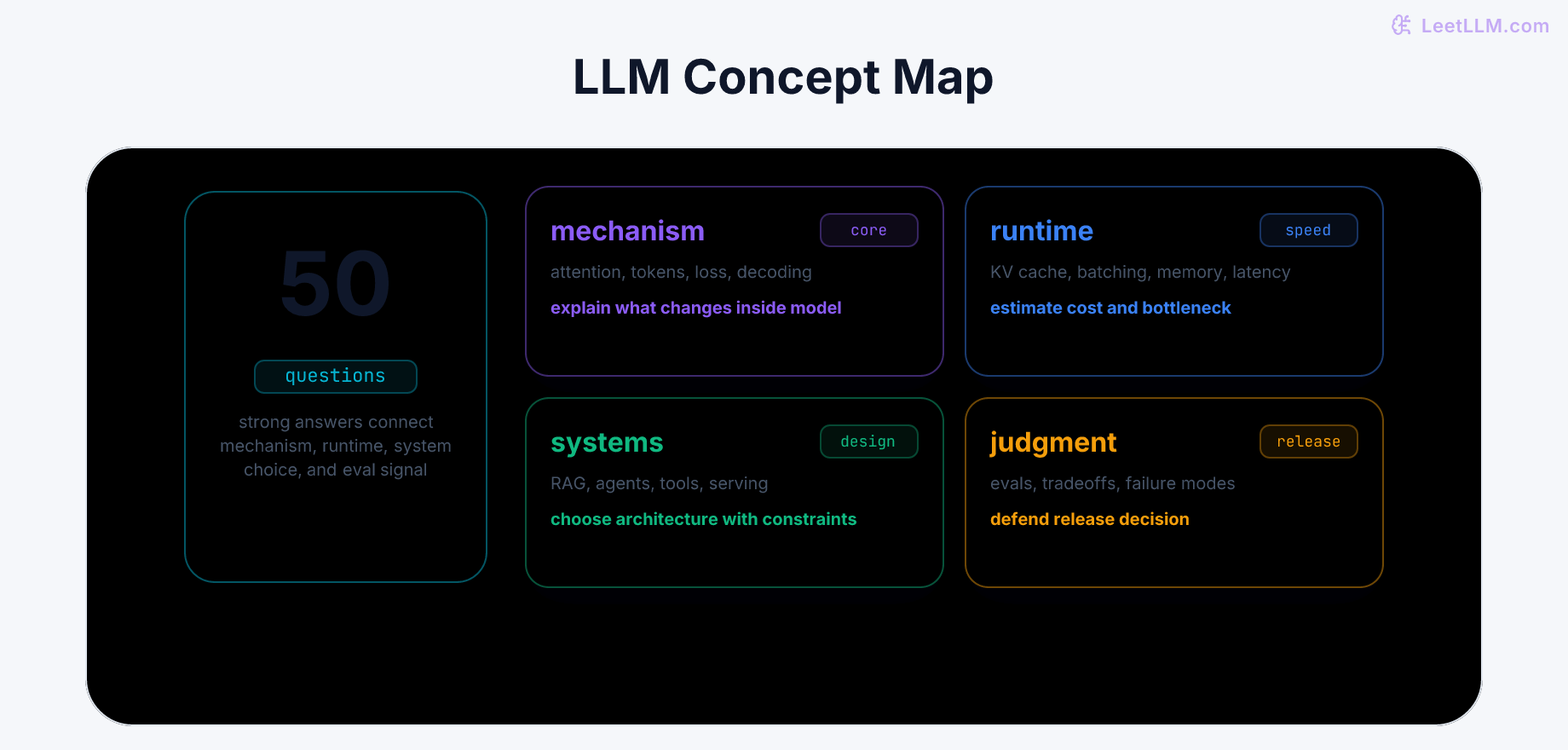
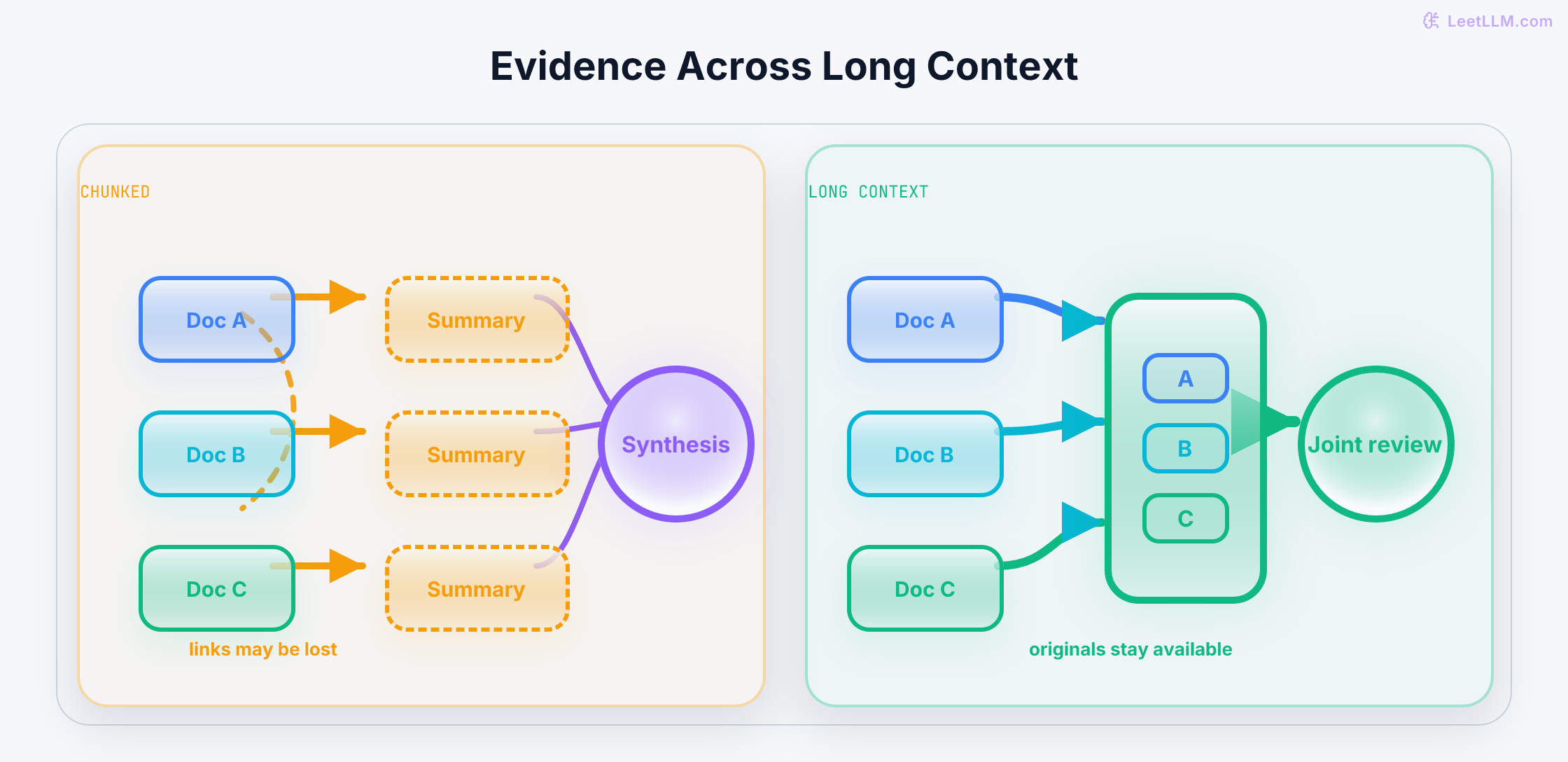
How LeetLLM turns research into curated lessons with research packets, article bundles, validation checks, generated diagrams, component-based illustrations, and a production web stack.
9 min
Read